Arquivo
WebCast pra amanhã 03-06
WebCast SQL Server
Material estudo, Query Processor
Estudar SQL Server? Como começar? – 2
Lista de Feeds:
Troubleshooting Microsoft SQL Server
http://blogs.msdn.com/chrissk/rss.xml
SQL Server Premier Field Engineer Posts / Rants..
http://blogs.msdn.com/sachinp/rss.xml
PFE Brasil – SQL Server
http://blogs.msdn.com/pfebrasilsql/rss.xml
Microsoft SQL Server Native Client team blog
http://blogs.msdn.com/sqlnativeclient/rss.xml
Zen and the Art of SQL Server Maintenance
http://blogs.msdn.com/mwilmot/rss.xml
Meio Bit – Notícias, Dicas, Internet, Informática, Tecnologia, Download
http://feeds.feedburner.com/meiobit
SQLblog.com – The SQL Server blog spot on the web
http://sqlblog.com/blogs/MainFeed.aspx
Ken Henderson’s WebLog
http://blogs.msdn.com/khen1234/rss.xml
Tips, Tricks, and Advice from the SQL Server Query Processing Team
http://blogs.msdn.com/sqlqueryprocessing/rss.xml
SQL Server , The BI Release
http://blogs.msdn.com/raulbalbuena/rss.xml
A SQL Server Blog
http://blogs.msdn.com/ashvinis/rss.xml
Bart Duncan’s SQL Weblog
http://blogs.msdn.com/bartd/rss.xml
CREATE DATABASE
http://blogs.msdn.com/gauravbi/rss.xml
Craig Freedman’s SQL Server Blog
http://blogs.msdn.com/craigfr/rss.xml
Conor vs. SQL
http://blogs.msdn.com/conor_cunningham_msft/rss.xml
Ian Jose’s WebLog
http://blogs.msdn.com/ianjo/rss.xml
Ben Miller’s World
http://dbaduck.com/feed/
Bill Ramos on SQL Server
http://blogs.msdn.com/billramo/rss.xml
Buck Woody – Database Administration – Carpe Datum
http://blogs.msdn.com/buckwoody/rss.xml
SQL, Analysis Services & related stories.
http://blogs.msdn.com/ikovalenko/rss.xml
Microsoft JobsBlog: Blog
http://feeds.feedburner.com/MicrosoftJobsBlog
CSS SQL Server Engineers
http://blogs.msdn.com/psssql/rss.xml
SQL Server Manageability Team Blog
http://blogs.msdn.com/sqlrem/rss.xml
Dan Guzman’s Blog
http://weblogs.sqlteam.com/dang/Rss.aspx
SQL Server Security
http://blogs.msdn.com/sqlsecurity/rss.xml
SQL Bloke Blogs
http://www.sqlbloke.com/sql-bloke-blogs/rss.xml
Euan Garden’s BLOG : SQL Server
http://blogs.msdn.com/euanga/rss.aspx?categoryid=7773
SQL Premier Field Engineering
http://blogs.msdn.com/menzos/rss.xml
rdoherty’s WebLog
http://blogs.msdn.com/rdoherty/rss.xml
Notes from SQL Server Premier Field Engineer
http://blogs.msdn.com/sqlpfe/rss.xml
Database Underground | Sean McCown
http://weblog.infoworld.com/dbunderground/rss.xml
Zach Skyles Owens
http://blogs.msdn.com/zowens/rss.xml
Tibor Karaszi
http://sqlblog.com/blogs/tibor_karaszi/rss.aspx
Microsoft SQL Server Development Customer Advisory Team
http://blogs.msdn.com/sqlcat/rss.xml
Slava Oks’s WebLog
http://blogs.msdn.com/slavao/rss.xml
Pedroso – SQL and Architecture Experience
http://blogs.msdn.com/pedroso/rss.xml
Microsoft SQL Server troubleshooting
http://blogs.msdn.com/joaol/rss.xml
Microsoft SQL ISV Program Management Team
http://blogs.msdn.com/mssqlisv/rss.xml
Brian Knight
http://pragmaticworks.com/community/blogs/brianknight/rss.aspx
Joe Sack’s SQL Server WebLog
http://feeds.feedburner.com/JoeSacksSqlServerWeblog
SQL, .NET and everything Microsoft
http://blogs.msdn.com/sanchan/rss.xml
TSQL_language’s WebLog
http://blogs.msdn.com/tsql_language/rss.xml
Sylvia’s SQL Center
http://blogs.msdn.com/sylviav/rss.xml
SQLServerPedia
http://feeds2.feedburner.com/sqlserverpedia
Inglesonline
http://feeds.feedburner.com/InglsOnline
EXEC dbo.LongTermMemory__Archive
http://dis4ea.blogspot.com/feeds/posts/default
GuntherB’s WebLog
http://blogs.msdn.com/guntherb/rss.xml
WesleyB’s Blog
http://blogs.msdn.com/wesleyb/rss.xml
Tech Crumbs
http://blogs.msdn.com/rafats/rss.xml
TechNet Magazine RSS Feed:
http://technet.microsoft.com/pt-br/magazine/rss/default.aspx
The SQL Doctor is In (Real In)
http://drsql.spaces.live.com/feed.rss
SQL Server Perceptions
http://weblogs.sqlteam.com/dmauri/Rss.aspx
Don Kiely’s Technical Blatherings
http://sqljunkies.com/WebLog/donkiely/rss.aspx
MohammedU’s space
http://mohammedu.spaces.live.com/feed.rss
Chad Boyd – 2
http://blogs.mssqltips.com/blogs/chadboyd/rss.aspx
Tecla SAP
http://feeds.feedburner.com/teclasap
The Synchronizer
http://blogs.msdn.com/Synchronizer/rss.xml
Michael Rys
http://blogs.msdn.com/mrys/rss.xml
Elizabeth Vitt
http://www.sqlskills.com/blogs/liz/SyndicationService.asmx/GetRss
Herleson Pontes – IT Professional
http://herleson.spaces.live.com/feed.rss
Robson Brandão
http://rbtech.spaces.live.com/feed.rss
SQL in Stockholm
http://blogs.msdn.com/grahamk/rss.xml
Brent Ozar – SQL Server DBA
http://feeds.feedburner.com/BrentOzar-SqlServerDba
SQLSkills Complete Team Blog
http://pipes.yahoo.com/pipes/pipe.run?_id=vv9PBOp13BGAc67kLO2fWQ&_render=rss
SQL Server Performance
http://blogs.msdn.com/sqlperf/rss.xml
SQL Server Brasil
http://blogs.technet.com/sqlserverbrasil/rss.xml
Syscomments…
http://weblogs.sqlteam.com/dinakar/Rss.aspx
snaps & snippets
http://milambda.blogspot.com/feeds/posts/default
Wandenkolk & SQL Server
http://sqlwanden.blogspot.com/feeds/posts/default
Blog do Alexandre Lopes
http://arodrigueslopes.spaces.live.com/feed.rss
Learn English – EnglishPod
http://englishpod.com/lessons/feed/
Ramblings of a DBA
http://feeds.feedburner.com/RamblingsOfADba
Fabiano Neves Amorim – SQL Server
http://fabianosqlserver.spaces.live.com/feed.rss
Christian Bolton – SQL Server Blog
http://sqlblogcasts.com/blogs/christian/rss.aspx
Eladio Rincón
http://feedproxy.google.com/EladioRincon
Inside SQL Server
http://blogs.msdn.com/matt_hollingsworth/rss.xml
TechNet Radio
http://www.microsoft.com/winme/0512/25568/technet_radio_mp3.xml
Jamie’s Junk
http://blogs.msdn.com/jamiemac/rss.xml
WinAjuda
http://feeds.feedburner.com/winajuda
Rafael Veronezi’s Weblog
http://rveronezi.wordpress.com/feed/
SQL Server User Education
http://blogs.msdn.com/sqlserverue/rss.xml
SQLTeam.com Feed
http://feeds.sqlteam.com/Sqlteam
With CLUE as (Select * from Random_Thought ORDER BY Common_Sense DESC)
http://weblogs.sqlteam.com/geoffh/Rss.aspx
with (nolock)
http://withnolock.com/communityserver/blogs/MainFeed.aspx
Grumpy Old DBA
http://sqlblogcasts.com/blogs/grumpyolddba/rss.aspx
SQL Programmability & API Development Team Blog
http://blogs.msdn.com/sqlprogrammability/rss.xml
Rob Farley
http://feeds.feedburner.com/robfarley
Tony Rogerson's ramblings on SQL Server
http://sqlblogcasts.com/blogs/tonyrogerson/rss.aspx
SQL Server Storage Engine & Tools (SSQA.net)
http://sqlserver-qa.net/blogs/tools/rss.aspx
SQL Server: um Endpoint Brasileiro
http://blogs.msdn.com/procha/rss.xml
Sql Stuff
http://blogs.msdn.com/chadboyd/rss.xml
English Experts
http://feeds.feedburner.com/EnglishExperts
Microsoft Certifications
http://blogs.msdn.com/gerryo/rss.xml
Data Platform Insider
http://blogs.technet.com/dataplatforminsider/rss.xml
Eventos Microsoft
http://www.msdnbrasil.com.br/Microsoft.RSS/RssEventos.ashx?ds_publico=dese|arq&DS_TIPO_EVENTO=web%20cast%20on%20line
SQL Protocols
http://blogs.msdn.com/sql_protocols/rss.xml
MCDBA Brasil
http://www.mcdbabrasil.com.br/rss.php
SQL Server Engine Tips
http://blogs.msdn.com/sqltips/rss.xml
SimonS Blog on SQL Server Stuff
http://feeds.feedburner.com/SimonsSqlServerStuff
Aaron’s space
http://vendoran.spaces.live.com/feed.rss
Inglês na Ponta da Língua
http://denilsodelima.blogspot.com/feeds/posts/default
Joe Webb
http://weblogs.sqlteam.com/joew/Rss.aspx
Glenn Berry’s SQL Server Performance
http://glennberrysqlperformance.spaces.live.com/feed.rss
MVP Brasil
http://mvpbrasil.spaces.live.com/feed.rss
Michael Aspengren
http://blogs.msdn.com/spike/rss.xml
Microsoft Midwest District SQL Server News
http://blogs.msdn.com/dpaulson/rss.xml
SQL Server 2008 Application Compatibility Blog
http://blog.scalabilityexperts.com/feed/
LUTI @ Microsoft
http://blogs.msdn.com/luti/rss.xml
sqldbatips.com blog
http://sqlblogcasts.com/blogs/sqldbatips/rss.aspx
Running SAP Applications on SQL Server
http://blogs.msdn.com/saponsqlserver/rss.xml
Microsoft SQL Server Release Services
http://blogs.msdn.com/sqlreleaseservices/rss.xml
David Portas’ Blog
http://blogs.conchango.com/davidportas/rss.aspx
SQL Server Compact – Compact & Capable
http://blogs.msdn.com/sqlservercompact/rss.xml
SQL Server 2008 (SSQA.net)
http://sqlserver-qa.net/blogs/sql2008/rss.aspx
The Premiers
http://sqlblogcasts.com/blogs/thepremiers/rss.aspx
Junior Galvão – MVP – SQL Server
http://juniorgalvao-mvp2007.spaces.live.com/feed.rss
Cihangir Biyikoglu – TSQLNet Weblog
http://blogs.msdn.com/cbiyikoglu/rss.xml
Vipul Shah’s SQL Blogs
http://blogs.technet.com/vipulshah/rss.xml
Beatrice Nicolini
http://blogs.technet.com/beatrice/rss.xml
Shashank Pawar
http://blogs.technet.com/sqlman/rss.xml
Alexey Yeltsov
http://blogs.technet.com/sqlthoughts/rss.xml
Elisabeth Redei – Ex, SQL Server Support
http://sqlblog.com/blogs/elisabeth_redei/rss.aspx
Diego Nogare
http://diegonogare.spaces.live.com/feed.rss
Gustavo Maia Aguiar
http://gustavomaiaaguiar.spaces.live.com/feed.rss
Blog do Luti
http://feeds2.feedburner.com/luticm
SQL Server Storage Engine
http://blogs.msdn.com/sqlserverstorageengine/rss.xml
Tips, Tricks, and Advice from the SQL Server Query Optimization Team
http://blogs.msdn.com/queryoptteam/rss.xml
Estudar SQL Server? Como começar? – 1
Aproveitando a resposta de um e-mail que escrevi para um Amigo, vou colar aqui, segue:
Faaaala Fabiano blz cara?
Parabens pelo blog,tenho acompanhado ele e esta muito bom,eu gostaria depois de te mandar um artigo que o paralelismo é muito ruim..rsrsrs…..vou te provar que é ruim…quais que tem sido sua fonte de tunning? Deixa seu telefone depois para trocarmos umas figurinhas q q vc acha?
Att
Escrever no blog me ajuda MUITO a aprender, começar a escrever foi uma dica que peguei com o Luciano Caixeta Moreira, alias ele foi o cara que me incentivou em muita coisa, devo muito a ele. Depois de todas as ajudas que ele me deu, fiquei com uma pergunta na cabeça, “Meu, porque o Luciano está fazendo isso por mim? O que ele ganha com isso?” … a resposta que vem em minha mente é, porque o cara é muito gente fina, não tem medo, nem o orgulho de ser “superior” aos outros.
Me manda o artigo sobre Paralelismo sim. Vou ler e mandar pro meu amigo Junior ele vai virar seu fã 🙂.
Sobre minhas fontes de Tunnig, se prepara porque eu aproveitei este e-mail para criar um post que fazia tempo que eu queria escrever.
O que eu faço para me manter atualizado, e aprender cada vez mais? Bom segue abaixo minha rotina de estudo, depois de ler você pode ser perguntar, “A mais ele não faz tudo isso”, sim eu faço.
Eu tenho lido MUITO coisa em blogs, no final deste post coloquei a lista com meus atuais RSSs. (Tive que colocar outro post, porque aqui na cabia)
Também não perco uma publicação dos artigos oficiais da Microsoft, já lançaram muita coisa boa, desde SQL 7.0 a 2008. Só por ai já tem coisa pra ler por 6 meses.
Sempre fico de olho nos posts de possíveis erros no site connect, leio sobre possíveis melhorias de tunning.
http://connect.microsoft.com/SQLServer
Baixo livros da Internet e leio capítulos que me interessam, outros leio inteiro. Compro livros, principalmente os que mais me interessam, por ex: os da Serie Internals da Denaley e os Training Kits.
Também vira e meche eu leio artigos MUITO técnicos, e excelentes do seguintes links:
http://research.microsoft.com/en-us/
http://www.sigmod.org/sigmod/index.html
http://www.sqlpass.org/LearningCenter/TechnicalArticles.aspx
Também sou assinante da SQL Server Magazine americana, e da SQL Magazine brasileira, na brasileira, está pra sair um artigo que escrevi sobre Query Processor. Espero que este mês finalmente saia a publicação(já fechamos o artigo faz uns 3 meses).
Também recebo e-mails de News dos seguintes sites:
http://www.sqlservercentral.com/
http://www.sql-server-performance.com/
http://searchsqlserver.techtarget.com/
http://www.linhadecodigo.com.br/
Também sempre tento assistir as WebCasts que tem por ai, seja da Quest, Idera, Microsoft. Tento ouvir PodCasts, RadioCasts, chats e entrevistas online. Procuro por eventos online, e vídeos de gravações de eventos. Tento achar vídeos sobre o assunto que estou querendo saber mais.
Fora isso, tento me manter o mais próximo possível dos fóruns MSDN e TechNet, aprendo muita coisa lá.
Quando tenho alguma dúvida em relação a algum problema interno do SQL, e não acho muita referência na internet, entro em contato direto com “os caras” da Microsoft.
Meu principal contato é o Conor, posso considerá-lo como meu mentor em SQL Server, o cara é gente finíssima, espero conhecê-lo pessoalmente em breve.
Conor Cunningham – Architect no Query Processor Team
Todos estes outros abaixo eu já troquei e-mail, e você pode estar pensando, e eles respondem? Sim, eles respondem. Claro que eu não fico pentelhando e abusando, com perguntas estúpidas. Mas sempre que preciso eles estão lá pra me dar um help.
Na lista abaixo, tem de tudo, PHDs formados em Harvard, MVPs e etc… só a “nata”.
Craig Freedman – SQL Engine
Bart Duncan – SQL Manageability Team
Cesar Galindo-Legaria – Development Lead
Boris Baryshnikov – SQL Engine
Surajit Chaudhuri – Principal Researcher
Kalen Delaney – Dispensa comentários…
Paul S. Randal – Dispensa comentários…
Kimberly L. Tripp – Dispensa comentários…
Luciano Moreira – Ex MS, Especialista em Desenvolvimento em SQL Server
Buck Woody – Program Manager
Eric Kang – SQL Developer, Escreveu a funcionalidade de Debug no SQL 2008
Richard Waymire – SQL Developer
Michael Rys – XML no SQL? é com ele.
Trika Harms zum Spreckel – Certificações
Gerry O’Brien – Certificações
Christian Kleinerman – SQL Engine
Jacob Sebastian – MVP SQL
Como remover uso de cursores, utilizando CTEs
Galera, vou publicar um e-mail que na época mandei apenas para o pessoal daqui da empresa, talvez a informação seja útil pra vocês.
—————————–
Pessoal a fim de informação segue uma dica de como transformar isso:

Nisso:

Sem usar cursor
DECLARE @Tab TABLE(Val_Min Int, Val_Max Int)
INSERT INTO @Tab(Val_Min, Val_Max) VALUES(1,3)
INSERT INTO @Tab(Val_Min, Val_Max) VALUES(15,20);
INSERT INTO @Tab(Val_Min, Val_Max) VALUES(6,9);
SELECT * FROM @TAB
— Cria tabela sequencial que vai de 1 a 100, pode ser qualquer tipo de tabela, neste caso usei a
— funcionalidade de CTE.
WITH Sequencial AS(
SELECT 1 as ID
UNION ALL
SELECT ID + 1
FROM Sequencial
WHERE ID < 100)
— Retorna os dados
SELECT Val_Min, Val_Max, ID
FROM @TAB a
INNER JOIN Sequencial s
ON s.ID >= a.Val_Min
AND s.ID <= a.Val_Max
ORDER BY a.Val_Min, a.Val_Max, s.ID
Esta tabela auxiliar que vai de 1 a 100, serve para bastante coisa.
Aproveito para refazer o convite de cadastrarem meu blog no RSS de seu outlook. Normalmente dicas como essa coloco lá, assim só lê quem tiver interesse.
Segue o link http://fabianosqlserver.spaces.live.com/feed.rss
É só cadastrar em Ferramentas\Configurações de Conta\RSS Feeds\
Produto Cartesiano e Query Optimizer
Galera, existem algumas situações onde o QO(Query Optimizer) simplesmente, decide remover uma instrução do join de uma consulta o que acaba gerando um inesperado Produto Cartesiano, ou seja, a mesma coisa que um join sem relacionamento, um cross join.
Por exemplo, imagine o seguinte código:
use tempdb
GO
declare @tab1 Table(a Int)
insert into @tab1
select TOP 1000 1
from sysobjects b, sysobjects a
set statistics io on
set statistics time on
select * from @tab1 a
inner join @tab1 b
on a.a = b.a
select * from @tab1 a
inner join @tab1 b
on a.a = b.a
where a.a = 1
set statistics io off
set statistics time off
A duas consultas acima retornam todos os registros ta tabela @tab1, mas existe uma grande diferença entre a primeira e a segunda consulta.
A primeira diferença que podemos notar é que a segunda consulta contem uma condição no where onde a.a tem que ser igual a 1. Ai é que ta, neste caso o QO sabe que existe uma redundância de comparação, pois se “a.a” é igual 1(where), e “a.a” é igual a “b.a” (join), logo ele sabe que b.a também será igual a 1. Portanto neste caso ele remove a condição do join (a.a = b.a) e aplica o filtro de “a = 1” nas tabelas “a” e “b”.
Este comportamento pode ser evidenciado ao analisarmos os planos de execução gerados. O plano da segunda consulta ficou assim:
| StmtText | Argument |
| select * from @tab1 a inner join @tab1 b on a.a = b.a where a.a = 1 | NULL |
| |–Nested Loops(Inner Join) | NULL |
| |–Table Scan(OBJECT:(@tab1 AS [b]), WHERE:(@tab1.[a] as [b].[a]=(1))) | OBJECT:(@tab1 AS [b]), WHERE:(@tab1.[a] as [b].[a]=(1)) |
| |–Table Scan(OBJECT:(@tab1 AS [a]), WHERE:(@tab1.[a] as [a].[a]=(1))) | OBJECT:(@tab1 AS [a]), WHERE:(@tab1.[a] as [a].[a]=(1)) |
Repare que na coluna argument o QO gerou apenas um argumento para a leitura das tabelas, e no Loop ele não gerou a condição de join. Isso caracteriza um Produto Cartesiano, onde para cada linha da tabela definida como “a”, o SQL vai ligar com todas as linhas da tabela “b”.
Ok, mas isso é ruim?… Sim neste caso sim… Pois para esta consulta utilizar um algoritmo de Hash para fazer o join seria muito mais eficaz. Para confirmar isso, basta verificar o plano gerado pela primeira consulta. Lembrando que ambas as consultas são relativamente iguais. Repare que o SQL gerou um Hash Join para fazer a ligação entre as tabelas.
|
StmtText |
Argument |
|
select * from @tab1 a inner join @tab1 b on a.a = b.a |
NULL |
|
|–Hash Match(Inner Join, HASH:([b].[a])=([a].[a]), RESIDUAL:(@tab1.[a] as [b].[a]=@tab1.[a] as [a].[a])) |
HASH:([b].[a])=([a].[a]), RESIDUAL:(@tab1.[a] as [b].[a]=@tab1.[a] as [a].[a]) |
|
|–Table Scan(OBJECT:(@tab1 AS [b])) |
OBJECT:(@tab1 AS [b]) |
|
|–Table Scan(OBJECT:(@tab1 AS [a])) |
OBJECT:(@tab1 AS [a]) |
Se analisarmos os resultados do statistics io e statistics time, veremos que a primeira consulta, utilizou menos tempo, IO e CPU para retornar os dados.
Primeira consulta (Hash Join):
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘#2E75B1C0’. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 328 ms, elapsed time = 19976 ms.
Segunda consulta (Loop Join):
Table ‘#2E75B1C0’. Scan count 2, logical reads 2002, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 407 ms, elapsed time = 20377 ms.
Bom, mas você pode estar pensando, bem, neste caso é só utilizar um hint para forçar o uso do Hash Join certo? Errado, se você tentar fazer isso vai receber a seguinte mensagem:
select * from @tab1 a
inner join @tab1 b
on a.a = b.a
where a.a = 1
option(hash join)
Msg 8622, Level 16, State 1, Line 20
Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
Como o SQL remove a condição do Join, ele terá que fazer um Produto Cartesiano e o SQL só consegue fazer isso utilizando o Loop Join L. Neste caso, o Hint colide com a Lógica do QO e gera o erro.
Como resolver o problema?….
Basta esperar a próxima versão do SQL, e torcer para que eles copiem o Oracle, que neste caso criou um parâmetro para tratar com este problema.
http://jonathanlewis.wordpress.com/2006/12/13/cartesian-merge-join/
Enviei este exemplo para o Boris Baryshnikov (SQL Server Engine), e ele me respondeu dizendo que estão trabalhando em uma correção para uma futura release.
Já existe um chamado no Connect falando sobre isso, portanto, só nos resta aguardar, e ficarmos atentos a este problema…
Entrevista – Eu mesmo :-)
Galera, como devem ter percebido nestas ultimas semanas estou um pouco distante dos fóruns e do Blog.
Estou trabalhando em um projeto de integração tecnológica entre 2 grandes instituições financeiras. Ainda não sei se posso dar mais detalhes portanto, por enquanto fica assim…
Como o projeto é bem grande, com certeza durante o andamento das fases do projeto, surgirão vários assuntos interessantes para compartilhar com vocês.
Prometo que assim que eu puder posto mais detalhes…
Por enquanto fiquem com a entrevista que a um tempo atrás, a pedido do Diego Nogare, eu mesmo respondi. As perguntas são as mesmas que fiz com alguns profissionais SQL Server.
Eu acho que não coloquei aqui no blog minhas respostas portanto… segue para quem não viu na revista.
1. Vamos começar falando da novidade do momento, quais as novas features do SQL Server 2008 que você acha mais importante, e porque? Nomeie pelo menos 3.
a. A que me fez parar e dizer UAU foram as implementações de Compression, Page Compression, Row Compression e Backup Compression, fiz alguns testes e me surpreendi com a qualidade de compressão de dados. Usei uma frase na WebCast de “Caminhos de Upgrade para SQL Server 2008”, – Imagina converter um livro de 1000 páginas para apenas 200, pois é mais ou menos isso que o algoritmo de compressão por página LZ78 criado pelos geeks seniors Lempel e Ziv faz.
1. Nos meus testes cheguei a seguinte conclusão.
|
Tabela |
CPU |
Writes |
Duration |
Tamanho |
Pages |
|
Tmp_Row_Compression |
10656 |
1617 |
45809 |
12 MB |
1613 |
|
Tmp_Page_Compression |
11359 |
1142 |
44118 |
8 MB |
1133 |
|
Tmp_Sem_Compression |
10032 |
5914 |
46873 |
46 MB |
5883 |
b. Filtered Index – Essa veio bem a calhar, poder escrever um comando desses vai ajudar e muito para quem tem tabelas muito grandes e com acesso a dados mais recentes, caso partition não for uma possibilidade, imagine o seguinte poderíamos criar um índice para cada período e gravar cada índice em um filegroup diferente que por sua vez estará em discos diferentes. Interesting… vale a pena estudar a fundo essa feature.
c. Resource Governor – Esse pode ser utilizado tanto em ambientes de produção como ambientes de teste, imagine o seguinte cenário(bem comum em desenvolvedoras de Software), Um servidor SQL Server distribuído para todos os desenvolvedores utilizarem para testes, desenvolvimento etc… Em um banco desses rola de tudo, select *, operações bulk insert, restore de backup, tudo ao mesmo tempo e sempre tem aqueles “comilões” de recurso que rodam tudo isso ao mesmo tempo J(eu não) , com o Resoruce Governor poderíamos limitar a quantidade de CPU e memória para que ele não pare o servidor enquanto trabalha.
2. Em relação a performance no SQL Server 2005, quais as features você acha mais importante?
a. O SQL 2005 comparado com o 2000, tem muitas, mas posso destacar a partition como uma excelente escolha para balanceamento de carga entre servidores diferentes, procure por Distributed Partitioned Views / Federatad Databases.
3. Quais suas dicas para um profissional que está iniciando em SQL Server?
a. Estudar muito e manter-se atualizado, se puder comece com um bom curso oficial Microsoft, caso não seja possível fazer o curso, existem MUITOS blogs e sites especializados em SQL Server que na minha opinião tem um conteúdo até melhor e mais aprofundado em cada tecnologia do SQL.
4. O que é necessário para se tornar um usuário Master em SQL Server?
a. Eu acho que somente com experiência e uma vivência diária de trabalho com o SQL Server o usuário poderá um dia dizer que é um Master em SQL Server. Mesmo assim tenho certeza que haverão situações em que até mesmo um super usuário terá que recorrer ao velho e bom senhor do conhecimento, “Pai-Google”.
5. O que é necessário para se tornar um usuário Master em Transact SQL Server?
a. Encontre uma empresa que tem um banco de dados com mais de 2 mil procedures e 3 mil functions e tabelas com mais de 200 milhões de registros e comece a tentar otimizar os códigos TSQL. Acredite ou não isso é MUITO comum de se encontrar, já trabalhei em algumas implementações de DW em diversos banco de dados e já vi alguns desses bancos. Caso não seja possível faça o seguinte, inicie um trace no profiler e abra a aplicação que roda no banco, comece dar os cliques e fazer as operações comuns do dia a dia dos usuários do software e depois veja os selects executados por sua aplicação e tente otimizá-los.
6. Qual sua opinião em relação ao uso excessivo de Triggers no banco de dados?
a. Eu não sou contra o uso de triggers mas tento evitá-las o máximo possível, na minha opinião elas só deixam o código mais complexo e mais pesado. Eu conversei com o Conor Cunningham(Super Plus Master Boss do time do Query Processor) sobre triggers. Vou deixar 2 links para meus posts falando Sobre Triggers.
1. Why triggers are Bad – Part I
1. http://fabianosqlserver.spaces.live.com/Blog/cns!52EFF7477E74CAA6!486.entry
2. Why triggers are Bad – Part II
1. http://fabianosqlserver.spaces.live.com/Blog/cns!52EFF7477E74CAA6!488.entry
7. Qual o maior erro que uma pessoa pode cometer ao analisar um plano de execução?
a. Sem dúvida é achar que um Index Seek é SEMPRE melhor que um Clustered Index Sacan. Ou então ver uma flecha indicando o uso de paralelismo e logo voltar no código para incluir um OPTION(MAXDOP 1).
8. Quando usar um Clustered Index e quando usar um Non Clustered Index?
a. Isso depende bastante de cada cenário, mas eu particularmente uso Int IDENTITY(1,1) para pks e deixo ela como meu índice cluster e os nonclustered para consultas onde poderei fazer um covered índex, onde o SQL terá que acessar apenas o nonclustered índex para ler toda as informações necessárias para retornar os dados da consulta.
9. Porque estatísticas são importantes?
a. Estatísticas estão a toda hora sendo utilizadas pelo query processor para conseguir gerar o melhor plano de execução para sua consulta. Por exemplo nas estatísticas ele poderá saber se o valor que você está procurando irá retornar 10 linhas ou então 10 milhões de linhas, neste caso ele poderia optar por usar paralelismo por ex.
10. O quanto fragmentação no banco de dados pode afetar performance? Existe algum beneficio em ter fragmentação no banco?
a. Physical fragmentation é quando você tem espaço livre nas páginas da tabela e isso em alguns casos pode ser uma coisa boa, já que irá evitar que o SQL efetue splits em futuros inserts e updates na tabela.
b. Logical fragmentation é quando a próxima página lógica não é contínua… Ou seja, o SQL não irá conseguir fazer um read-ahead o que sempre será ruim. Confesso que fiquei curioso em relação a algum cenário onde esse tipo de fragmentação seria uma coisa boa, entrei em contato com nada mais nada menos que a Kimberly Trip e para minha surpresa após 1 hora que eu havia enviado o e-mail ela me respondeu dizendo que ela não via nenhum cenário onde esse tipo de fragmentação poderia ser benéfica, e mais, ela respondeu com cópia para o Paul Randal perguntando a opinião dele e logo depois ele também respondeu dizendo a mesma coisa. Portanto me fiz por satisfeito com as respostas J.
11. Afinal paralelismo é bom ou ruim?
a. Na minha opinião Paralelismo é bom. O que acontece é que em alguns casos onde temos uma pressão de CPU no servidor e o SQL optou por por fazer uma determinada consulta utilizando paralelismo, depois disso, o servidor recebeu outras requisições que demandavam muito mais CPU, neste caso a coisa pode ficar feia. L
12. Você utiliza alguma ferramenta para auxiliar na resolução de problemas de performance? Quais?
a. Profiler e SSMS são minha prediletas, as ferramentas de gerenciamento da Idera e da Quest são muito boas, mas é difícil convencer alguém de que o alto custo delas vale a pena.
13. Em um banco de dados em produção você utiliza algum TraceFlag habilitado?
a. Sim o 1118 para que o SQL não aloque mais extends mistos e sempre aloque extends uniformes, evitando uma possível contenção na TempDB que na teoria é a maior utilizada pela controladora SGAM já que as tabelas temporárias casualmente são pequenas.
14. Cite 3 livros que não podem faltar na coleção de um especialista SQL Server.
a. Inside SQL Server 2000 e todos da Série Inside Microsoft SQL Server 2005.
15. Nestes anos de experiência, Qual foi o problema mais difícil de resolver que encontrou?
a. Com certeza foi na otimização de uma proc com 2500 linhas que como vocês podem imaginar efetuava vários processos super complexos, depois de muito brigar com ela, mudei bastante coisa e no fim deu tudo certo J.
16. Já passou por algum daqueles problemas que resolveu mas até hoje não sabe o que era?
a. Direto, e quanto acontece isso faço o seguinte, para tudo, fecha, apaga e começa novamente, sempre deu certo, mas não me pergunte qual era o problema.
17. Qual o maior banco de dados que já trabalhou e quantas linhas tinha a maior tabela que já viu?
a. O banco de dados de um de nossos clientes, 200 gb e tabelas com mais de 250 milhões de registros, punk. Tem noção do tempo que demora pra reindexar ela?
18. Como diria o Tobby(charges.com.br) – Bate bola jogo rápido:
a. Um concorrente digno do SQL Server: Oracle para Grandes BDs, Firebird contra a Versão Express.
b. Uma feature: Compression.
19. Um comando SQL(o meu predileto é o SHUTDOWN WITH NOWAIT J) : SHUTDOWN WITH NOWAIT
20. Você tem algum blog? Site? Msn?… Como os usuários da comunidade podem entrar em contato com você?
a. E-Mail: fabiano_amorim@bol.com.br
b. Blog: http://fabianosqlserver.spaces.live.com/blog/
c. Msn: fabianonevesamorim@hotmail.com
21. Deseja deixar alguma consideração final?
a. “É melhor ser criticado pelos sábios do que ser elogiado pelos insensatos. Elogios vazios são como gravetos atirados em uma fogueira.” Eclesiastes.
Parameters and Stored Procedures
Semana passada eu escrevi um
post rápido falando sobre um problema de performance que ocorreu em um de
nossos clientes.
Vamos entender direito o problema para caso vocês passem por isso, saibam
como evitar, ou como investigar o que está acontecendo.
Um pouco de “Parameter Sniifing”
Antes de começar com o código deixa eu explicar uma coisa,
Sempre que uma procedure é executada, e o Query Processor não encontra um
plano de execução no Cache, ele da inicio a uma sério de passos que irão gerar
um plano de execução para a consulta. Sabemos que uma procedure contem vários
comandos e cada um deles tem o seu plano de execução. Estes planos são gerados
durante a execução da consulta, ou seja, durante a execução do batch, na fase de
compilação da proc. Ao efetuar um exec proc… o SQL gera o plano de todos os
comandos de dentro do batch de uma só vez. Com os planos gerados, o Query
Execution Engine vai executando os planos.
Para estimar a cardinalidade
das consultas de dentro da proc, o QO(Query Optimizer) executa um processo
chamado de Sniffing, ou seja, ele lê os valores dos parâmetros de entrada da
proc e utiliza estes valores para fazer a estimativa. Esta estimativa é
extremamente importante pois uma má estimativa pode gerar planos de execução
ineficientes(como veremos mais abaixo).
Veja bem, eu já vi pessoas dizendo que Parameter Sniffing é um problema, na
verdade ele pode causar problemas, mas geralmente é um excelente recurso.
Veremos 2 tipos de problemas que podem ser causados por causa de um “Bad
Sniffing” J.
Quando o Sniffing funciona
Vamos imaginar a seguinte proc:
1: CREATE PROCEDURE st_proc @Valor Int 2: AS 3: SELECT * 4: FROM TabTeste 5: WHERE Valor <= @Valor
Ao executar esta proc, se o valor passado para a variável @Valor for
altamente seletivo,
ou seja, irá fazer com que a consulta retorne poucas linhas, então é bem
provável que o SQL utilize um possível índice na coluna valor e depois faça um
bookmark
para ler os dados que não estão no índice.
Bom, mas em tempo de compilação(geração do plano) da proc, como o SQL sabe se
o valor é bastante seletivo ou não?. Ele lê (sniff) o valor de @Valor e usa este
valor para ver a seletividade
e cardinalidade
nas estatísticas
do índice.
Tendo o valor para ser analisado nas estatísticas o SQL pode gerar o plano
mais adequado conforme este valor.
Quando o Sniffing não funciona 1
Vamos imaginar a seguinte proc:
1: CREATE PROCEDURE st_proc @Valor Int 2: AS 3: DECLARE @Variavel_Auxiliar Int 4: SET @Variavel_Auxiliar = @Valor; 5: SELECT * 6: FROM TabTeste 7: WHERE Valor <= @Variavel_Auxiliar
Quando utilizamos variáveis auxiliares nas procs, em tempo de compilação, o
SQL não consegue estimar qual será o valor da variável @Variavel_Auxiliar,
portanto ele não tem como fazer as estimativas necessárias para decidir qual
plano gerar. No tópico 5 deste
post, eu já falei o que o SQL faz quando ele não consegue estimar a
cardinalidade de um valor.
Se ele não consegue estimar ele vai, “chutar”, neste caso(sinal de <=) a
estimativa será de 30% do tamanho da tabela. E posso te garantir que com uma
estimativa de 30% da tabela, com certeza o SQL não vai gerar um BookMark, pois
com esta estimativa é mais performático fazer um Scan. Mesmo que este Scan seja
para ler apenas 1 linha. Lembre-se que o SQL não sabe que é só 1 linha que será
retornada, para ele, será retornada 30% da tabela.
Quando o Sniffing não funciona 2
Vamos imaginar a seguinte proc,
1: CREATE PROCEDURE st_proc @Valor Int 2: AS 3: IF @Valor = 0 4: SET @Valor = 10; 5: SELECT * 6: FROM TabTeste 7: WHERE Valor <= @Valor
Este foi o problema que aconteceu com nosso cliente. Havia uma procedure onde
o valor do parâmetro de entrada era alterado durante a execução da proc. Se a
chamada da procedure fosse @Valor = 0, então o valor seria alterado para 10
fazendo com que a estimativa inicial utilizada pelo SQL Server ficasse
incorreta.
Independente de o valor do parâmetro de entrada ser alterado, para a
compilação da procedure, o SQL vai utilizar o valor recebido inicialmente, ou
seja, o valor informado na execução da procedure. Se eu passar o valor 0, o SQL
vai usar este valor para estimar a cardinalidade da coluna. Digamos que esta
consulta resulta em uma estimativa de retorno de apenas 1 linha, e o SQL decide
utilizar um índice pela coluna valor mais um bookmark. Porem com a alteração do
parâmetro a consulta passará a retornar 1000 linhas. Neste cenário teríamos um
péssimo plano.
Exemplificando
Para exemplificar os problemas mencionados acima, criei uma tabela chamada
TabTeste, com um índice nonclustered na coluna Valor e uma proc que faz alguns
selects nesta tabela.
Nesta proc, temos os 3 casos mencionados acima, onde a 1º consulta faz a
estimativa correta, a segunda consulta utiliza a variável auxiliar e por fim uma
consulta que faz um select utilizando a variável após sofrer uma alteração.
1: USE TEMPDB
2: GO
3: SET NOCOUNT ON;
4:
5: IF OBJECT_ID('tempdb.dbo.TabTeste') IS NOT NULL
6: DROP TABLE TabTeste
7: GO
8: IF OBJECT_ID('tempdb.dbo.st_Proc_Teste') IS NOT NULL
9: DROP PROC st_Proc_Teste
10: GO
11: CREATE TABLE TabTeste(ID Int Identity(1,1) Primary Key,
12: Nome VarChar(200) NOT NULL,
13: Valor Int NOT NULL)
14: GO
15: DECLARE @i INT
16: SET @i = 0
17: WHILE (@i < 50000)
18: BEGIN
19: INSERT INTO TabTeste(Nome, Valor)
20: VALUES(NEWID(), ABS(CHECKSUM(NEWID()) / 1000000) + 1)
21: SET @i = @i + 1
22: END;
23: GO
24: INSERT INTO TabTeste(Nome, Valor) VALUES(NEWID(), 0)
25: INSERT INTO TabTeste(Nome, Valor) VALUES(NEWID(), 0)
26: INSERT INTO TabTeste(Nome, Valor) VALUES(NEWID(), 0)
27: GO
28: CREATE NONCLUSTERED INDEX IX_Index ON TabTeste(Valor);
29: GO
30: CREATE PROCEDURE dbo.st_Proc_Teste @Valor Int
31: AS
32: BEGIN
33: DECLARE @Variavel_Auxiliar Int
34: SELECT @Variavel_Auxiliar = @Valor;
35: -- Variável original sem alterar
36: SELECT *
37: FROM TabTeste
38: WHERE Valor <= @Valor
39: -- Variável auxiliar
40: SELECT *
41: FROM TabTeste
42: WHERE Valor <= @Variavel_Auxiliar
43: IF @Valor = 0
44: SET @Valor = 10;
45: -- Variável original alterada
46: SELECT *
47: FROM TabTeste
48: WHERE Valor <= @Valor
49: END
Vamos executar a proc e visualizar os dados retornados.
EXEC dbo.st_Proc_Teste @Valor = 0
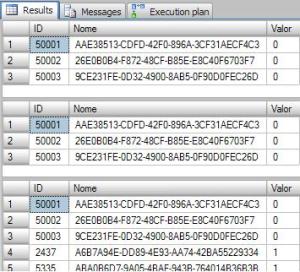
Para as consulta 1 e 2 podemos observar que são retornadas apenas 3 linhas,
já que na tabela TabTeste só existem 3 valores onde o valor da coluna “Valor”
seja menor ou igual a 0. Já na terceira consulta, o valor utilizado no where foi
o valor “10”, já que ele foi alterado em tempo de execução. Neste caso várias
linhas serão retornadas. Não apenas 3.
Para as consultas 1 e 2, com certeza fazer utilizar o índice nonclustered e
fazer um Bookmark é a melhor opção de acesso aos dados, já para a 3º consulta é
bem provável que o ideal seria fazer um Scan já que vários registros serão
retornados.
Vamos ver o que aconteceu:

Figura – 1º Plano
Podemos observar que a estimativa de quantidade de linhas que seriam
retornadas foi precisa, já foi estimado 3 e o número atual de linhas retornadas
também foi 3. Aqui podemos ver que o Sniff foi de grande valor.

Figura – 2º Plano
Aqui já podemos ver que o SQL não utilizou o índice, e sim gerou um Clustered
Index Scan, mas porque ele não utilizou o Índice? Bom, a resposta está facil,
ele gerou uma estimativa incorreta. Como utilizamos a variável auxiliar o SQL
estimou que 30% da tabela ou seja, 15000 linhas seriam retornadas, e para
retornar 15 mil linhas compensaria fazer o Scan. Mas podemos observar que a
quantidade de linhas atuais é de apenas 3.
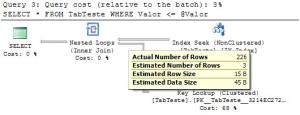
Figura – 3º Plano
Já o 3º plano utilizou o Índice gerando assim um Idex Seek, mas perai.
Quantas linhas ele estimou? Apenas 3. E quantas foram retornadas? 226. Com
certeza neste caso seria melhor ele gerar um Scan do que fazer o Seek +
Bookmark.
Ora, mas porque ele gerou o bookmark, isso porque para fazer a estimativa,
ele utilizou o valor passado no parâmetro de entrada.
Statistics IO
Para comprovar que o 2º e 3º plano geraram planos incorretos, basta
analisarmos a quantidade de IOs gerados para retornar os dados de cada consulta.

Nas consultas 2 e 3, o número de IOs foi bem alto. O número de IOs efetuados
pela consulta 2 deveria ser igual ao número da consulta 1, já que ambas retornam
os mesmo registros.
Para confirmar se na consulta 3 realmente compensava fazer um Scan ao invéz
de um Seek + BookMark, podemos simplesmente olhar quantos IOs foram necessários
para fazer um Scan na tabela(consulta 2).
Visualizando os valores utilizados pelos parâmetros
Para confirmar quais valores foram utilizados nas consultas, podemos analisar
a propriedade ParameterList nas propriedadeos do plano. Para isso, clique com o
botão do lado direito do mouse no operador de select no plano de execução, e
escolha a opção “Properties”, depois veja a propriedade “Parameter List“.

Propriedades – 1º Consulta
O valor utilizado no momento de compilação foi o mesmo utilizado no momento
de RunTime.
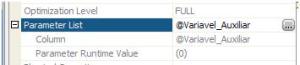
Propriedades – 2º Consulta
O QO não conseguiu utilizar nenhum valor, portanto ele não aparece. Neste
caso ele utilizou os 30%.
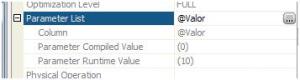
Propriedades – 3º Consulta
O valor utilizado no momento de compilação foi “0” porem no mento de RunTime
o valor mudou para “10”.
Conclusão
Bom galera, fica a dica de quando, como e porque estes problemas são
causados. Depois de entendido o problema resolve-los fica bem mais facil.
Abraço.
Profissional 5 estrelas, minhas considerações
Galera, fiz as provas do programa de profissional 5 estrelas de SQL Server no TechNet. Fiz o update do meu transcript para conseguir a 5º estrela, já que é necessário provar que você fez o exame 70-431 para obter a 5º estrela. Daqui a 72 horas úteis(nem sei quanto da isso em dias…) a 5º estrela deve aparecer no meu nome.
Segue minhas considerações em relação ao programa.
Bom, a uns 9 anos atrás quando eu ainda estava na fase pesada de estudos de informática, pra mim o programa foi bem interessante, cheguei a fazer várias provas de Segurança, ASP, C#, VB, .NET e etc… Na época isso foi legal e tals, e até que serviu bastante pra me ajudar a estudar sobre as tecnologias MS.
Mas hoje, penso que o programa deveria ser diferente. Se eu parar pra pensar, pra mim, para o que servem estas estrelas?
Acho que pra nada, na melhor das hipóteses para mim serviu como passatempo. Creio que a MS deveria ter um programa de incentivo para profissionais qualificados com 5 estrelas. Existem várias formas de fazer isso, seja divulgando melhor o nome deles, dar prêmios, descontos de softwares, voucher para certificação, convites para eventos, e por ai vai.. pensar em como fazer isso não problema meu é problema deles.. e eles tem pessoal de Marketing muito melhores do que eu para pensar nisso…
Considerações em ao material de estudo.
Os materiais são bem interessantes, mas é pouca coisa. O MSDN e TechNet tem MUITA coisa sobre SQL Server, portanto seria mais um “juntar” tudo e disponibilizar como material. Não precisa criar muita coisa nova, quase tudo já existe.
Por falar em juntar, na minha opinião ter tanta coisa em lugar separados é um grande problema, se é que podemos chamar isso de problema. Não tenho palavras para agradecer, todo o conteúdo que a MS disponibiliza para os profissionais que trabalham com seus softwares mas, isso não esta organizado. Nem um pouco organizado, tem coisa pra todo lado: MSDN, Technet, Support, Blogs, WebCasts, ScreenCasts, PodCasts, RadioCasts, Chats … se eu fosse listar todos os sites que tenho em favoritos relacionados a estudos daria mais de 200… Ei estou falando só sobre SQL Server, imagina se pegarmos os conteúdos de Win… o dia em que eu tiver tempo vou atualizar minha lista de Blogs e vocês vão entender melhor o que eu estou dizendo.
Considerações em relação as provas.
Para quem fez o exame 70-431 e tem o livro de treinamento, as perguntas chegam a dar vergonha. Simplesmente 80 % das perguntas são exatamente as mesmas feitas no livro. Na minha opinião o famoso ctrl-c ctrl-v entrou em ação. O que é uma pena de ser ver. Aproveitando o pena, outra coisa chata é o título da página de ranking completo, “Untitled Page” sensacional.
Algumas perguntas estão escritas parte em inglês parte em português, por exemplo, pergunta em português e resposta em inglês. Como as perguntas foram traduzidas do livro, algumas foram até traduzidas incorretamente.
Eu não gosto disso. Na minha opinião ou é tudo em inglês ou tudo em português, ok, eu sei que tem algumas palavras ou mesmo expressões que é melhor deixar em inglês, mas como eu disse, isso são “algumas”.
Isso me lembra alguns projetos que trabalhei que envolviam empresas multinacionais. Comumente recebo documentos escritos metade em inglês e a outra metade em espanhol, e as vezes os dois misturados, isso sem contar com os comentários em português.
A sim é uma multinacional, então tudo bem, tudo bem nada. Pra mim é falta de organização, escolhe um idioma e todos tem que usar o mesmo e ponto.
Conteúdo para profissionais que finalizaram as 5º estrelas.
Ok, ganhei a 5º estrela, e agora?
O MSDN e TechNet dão muito valor aos profissionais que estão iniciando, não estou dizendo que isso é ruim, eu me lembro muito bem que um dia eu precisei desse valor. Mas para quem já tem um pouco de experiência com SQL Server, não temos muita coisa avançada. Quantas WebCasts nível 300,400 você já assistiu? Ok talvez algumas, mas com certeza nenhuma em português. Quantos artigos, ou programas são disponibilizados com um conteúdo mais focado para profissionais já certificados, pouquíssimos(no momento não me lembro de nenhum).
Ok, eu sei que alguns profissionais MS estão empenhados em ajudar o conteúdo disponibilizado para a comunidade, eu realmente admiro essa ação, mas sei que sozinhos, conseguem muito pouco.
Sinceramente, eu ADORO quando leio um texto e ao terminar de ler não tenho a menor idéia do que li J. Assim eu leio denovo, e denovo… até entender. Esses tipo de conteúdo que eu quero ver. Quer alguns exemplos?
A look at Virtual Address Space – VAS
How It Works: SQL Server Page Allocations
How It Works: SQLIOSim – Checksums
Conclusão
Bom galera, a pergunta que fica é: Vale a pena obter as 5 estrelas?
Na minha opinião a resposta é sim. Mas eu realmente gostaria que um dia este meu “sim” soasse como “Cara essa você não pode perder”.
Abraço.

Fabiano Amorim
SQL Server MVP

Meu livro, Complete ShowPlan Operators

Livro, SQL Server além do conceito

Livro, Diálogos ao vento

Livro, Diálogos com D
