Parameters and Stored Procedures
Semana passada eu escrevi um
post rápido falando sobre um problema de performance que ocorreu em um de
nossos clientes.
Vamos entender direito o problema para caso vocês passem por isso, saibam
como evitar, ou como investigar o que está acontecendo.
Um pouco de “Parameter Sniifing”
Antes de começar com o código deixa eu explicar uma coisa,
Sempre que uma procedure é executada, e o Query Processor não encontra um
plano de execução no Cache, ele da inicio a uma sério de passos que irão gerar
um plano de execução para a consulta. Sabemos que uma procedure contem vários
comandos e cada um deles tem o seu plano de execução. Estes planos são gerados
durante a execução da consulta, ou seja, durante a execução do batch, na fase de
compilação da proc. Ao efetuar um exec proc… o SQL gera o plano de todos os
comandos de dentro do batch de uma só vez. Com os planos gerados, o Query
Execution Engine vai executando os planos.
Para estimar a cardinalidade
das consultas de dentro da proc, o QO(Query Optimizer) executa um processo
chamado de Sniffing, ou seja, ele lê os valores dos parâmetros de entrada da
proc e utiliza estes valores para fazer a estimativa. Esta estimativa é
extremamente importante pois uma má estimativa pode gerar planos de execução
ineficientes(como veremos mais abaixo).
Veja bem, eu já vi pessoas dizendo que Parameter Sniffing é um problema, na
verdade ele pode causar problemas, mas geralmente é um excelente recurso.
Veremos 2 tipos de problemas que podem ser causados por causa de um “Bad
Sniffing” J.
Quando o Sniffing funciona
Vamos imaginar a seguinte proc:
1: CREATE PROCEDURE st_proc @Valor Int 2: AS 3: SELECT * 4: FROM TabTeste 5: WHERE Valor <= @Valor
Ao executar esta proc, se o valor passado para a variável @Valor for
altamente seletivo,
ou seja, irá fazer com que a consulta retorne poucas linhas, então é bem
provável que o SQL utilize um possível índice na coluna valor e depois faça um
bookmark
para ler os dados que não estão no índice.
Bom, mas em tempo de compilação(geração do plano) da proc, como o SQL sabe se
o valor é bastante seletivo ou não?. Ele lê (sniff) o valor de @Valor e usa este
valor para ver a seletividade
e cardinalidade
nas estatísticas
do índice.
Tendo o valor para ser analisado nas estatísticas o SQL pode gerar o plano
mais adequado conforme este valor.
Quando o Sniffing não funciona 1
Vamos imaginar a seguinte proc:
1: CREATE PROCEDURE st_proc @Valor Int 2: AS 3: DECLARE @Variavel_Auxiliar Int 4: SET @Variavel_Auxiliar = @Valor; 5: SELECT * 6: FROM TabTeste 7: WHERE Valor <= @Variavel_Auxiliar
Quando utilizamos variáveis auxiliares nas procs, em tempo de compilação, o
SQL não consegue estimar qual será o valor da variável @Variavel_Auxiliar,
portanto ele não tem como fazer as estimativas necessárias para decidir qual
plano gerar. No tópico 5 deste
post, eu já falei o que o SQL faz quando ele não consegue estimar a
cardinalidade de um valor.
Se ele não consegue estimar ele vai, “chutar”, neste caso(sinal de <=) a
estimativa será de 30% do tamanho da tabela. E posso te garantir que com uma
estimativa de 30% da tabela, com certeza o SQL não vai gerar um BookMark, pois
com esta estimativa é mais performático fazer um Scan. Mesmo que este Scan seja
para ler apenas 1 linha. Lembre-se que o SQL não sabe que é só 1 linha que será
retornada, para ele, será retornada 30% da tabela.
Quando o Sniffing não funciona 2
Vamos imaginar a seguinte proc,
1: CREATE PROCEDURE st_proc @Valor Int 2: AS 3: IF @Valor = 0 4: SET @Valor = 10; 5: SELECT * 6: FROM TabTeste 7: WHERE Valor <= @Valor
Este foi o problema que aconteceu com nosso cliente. Havia uma procedure onde
o valor do parâmetro de entrada era alterado durante a execução da proc. Se a
chamada da procedure fosse @Valor = 0, então o valor seria alterado para 10
fazendo com que a estimativa inicial utilizada pelo SQL Server ficasse
incorreta.
Independente de o valor do parâmetro de entrada ser alterado, para a
compilação da procedure, o SQL vai utilizar o valor recebido inicialmente, ou
seja, o valor informado na execução da procedure. Se eu passar o valor 0, o SQL
vai usar este valor para estimar a cardinalidade da coluna. Digamos que esta
consulta resulta em uma estimativa de retorno de apenas 1 linha, e o SQL decide
utilizar um índice pela coluna valor mais um bookmark. Porem com a alteração do
parâmetro a consulta passará a retornar 1000 linhas. Neste cenário teríamos um
péssimo plano.
Exemplificando
Para exemplificar os problemas mencionados acima, criei uma tabela chamada
TabTeste, com um índice nonclustered na coluna Valor e uma proc que faz alguns
selects nesta tabela.
Nesta proc, temos os 3 casos mencionados acima, onde a 1º consulta faz a
estimativa correta, a segunda consulta utiliza a variável auxiliar e por fim uma
consulta que faz um select utilizando a variável após sofrer uma alteração.
1: USE TEMPDB
2: GO
3: SET NOCOUNT ON;
4:
5: IF OBJECT_ID('tempdb.dbo.TabTeste') IS NOT NULL
6: DROP TABLE TabTeste
7: GO
8: IF OBJECT_ID('tempdb.dbo.st_Proc_Teste') IS NOT NULL
9: DROP PROC st_Proc_Teste
10: GO
11: CREATE TABLE TabTeste(ID Int Identity(1,1) Primary Key,
12: Nome VarChar(200) NOT NULL,
13: Valor Int NOT NULL)
14: GO
15: DECLARE @i INT
16: SET @i = 0
17: WHILE (@i < 50000)
18: BEGIN
19: INSERT INTO TabTeste(Nome, Valor)
20: VALUES(NEWID(), ABS(CHECKSUM(NEWID()) / 1000000) + 1)
21: SET @i = @i + 1
22: END;
23: GO
24: INSERT INTO TabTeste(Nome, Valor) VALUES(NEWID(), 0)
25: INSERT INTO TabTeste(Nome, Valor) VALUES(NEWID(), 0)
26: INSERT INTO TabTeste(Nome, Valor) VALUES(NEWID(), 0)
27: GO
28: CREATE NONCLUSTERED INDEX IX_Index ON TabTeste(Valor);
29: GO
30: CREATE PROCEDURE dbo.st_Proc_Teste @Valor Int
31: AS
32: BEGIN
33: DECLARE @Variavel_Auxiliar Int
34: SELECT @Variavel_Auxiliar = @Valor;
35: -- Variável original sem alterar
36: SELECT *
37: FROM TabTeste
38: WHERE Valor <= @Valor
39: -- Variável auxiliar
40: SELECT *
41: FROM TabTeste
42: WHERE Valor <= @Variavel_Auxiliar
43: IF @Valor = 0
44: SET @Valor = 10;
45: -- Variável original alterada
46: SELECT *
47: FROM TabTeste
48: WHERE Valor <= @Valor
49: END
Vamos executar a proc e visualizar os dados retornados.
EXEC dbo.st_Proc_Teste @Valor = 0
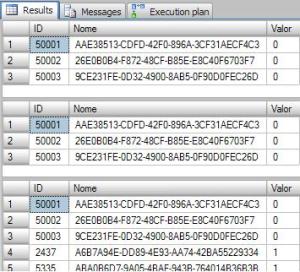
Para as consulta 1 e 2 podemos observar que são retornadas apenas 3 linhas,
já que na tabela TabTeste só existem 3 valores onde o valor da coluna “Valor”
seja menor ou igual a 0. Já na terceira consulta, o valor utilizado no where foi
o valor “10”, já que ele foi alterado em tempo de execução. Neste caso várias
linhas serão retornadas. Não apenas 3.
Para as consultas 1 e 2, com certeza fazer utilizar o índice nonclustered e
fazer um Bookmark é a melhor opção de acesso aos dados, já para a 3º consulta é
bem provável que o ideal seria fazer um Scan já que vários registros serão
retornados.
Vamos ver o que aconteceu:

Figura – 1º Plano
Podemos observar que a estimativa de quantidade de linhas que seriam
retornadas foi precisa, já foi estimado 3 e o número atual de linhas retornadas
também foi 3. Aqui podemos ver que o Sniff foi de grande valor.

Figura – 2º Plano
Aqui já podemos ver que o SQL não utilizou o índice, e sim gerou um Clustered
Index Scan, mas porque ele não utilizou o Índice? Bom, a resposta está facil,
ele gerou uma estimativa incorreta. Como utilizamos a variável auxiliar o SQL
estimou que 30% da tabela ou seja, 15000 linhas seriam retornadas, e para
retornar 15 mil linhas compensaria fazer o Scan. Mas podemos observar que a
quantidade de linhas atuais é de apenas 3.
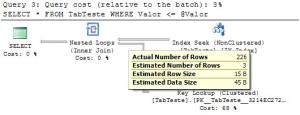
Figura – 3º Plano
Já o 3º plano utilizou o Índice gerando assim um Idex Seek, mas perai.
Quantas linhas ele estimou? Apenas 3. E quantas foram retornadas? 226. Com
certeza neste caso seria melhor ele gerar um Scan do que fazer o Seek +
Bookmark.
Ora, mas porque ele gerou o bookmark, isso porque para fazer a estimativa,
ele utilizou o valor passado no parâmetro de entrada.
Statistics IO
Para comprovar que o 2º e 3º plano geraram planos incorretos, basta
analisarmos a quantidade de IOs gerados para retornar os dados de cada consulta.

Nas consultas 2 e 3, o número de IOs foi bem alto. O número de IOs efetuados
pela consulta 2 deveria ser igual ao número da consulta 1, já que ambas retornam
os mesmo registros.
Para confirmar se na consulta 3 realmente compensava fazer um Scan ao invéz
de um Seek + BookMark, podemos simplesmente olhar quantos IOs foram necessários
para fazer um Scan na tabela(consulta 2).
Visualizando os valores utilizados pelos parâmetros
Para confirmar quais valores foram utilizados nas consultas, podemos analisar
a propriedade ParameterList nas propriedadeos do plano. Para isso, clique com o
botão do lado direito do mouse no operador de select no plano de execução, e
escolha a opção “Properties”, depois veja a propriedade “Parameter List“.

Propriedades – 1º Consulta
O valor utilizado no momento de compilação foi o mesmo utilizado no momento
de RunTime.
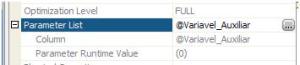
Propriedades – 2º Consulta
O QO não conseguiu utilizar nenhum valor, portanto ele não aparece. Neste
caso ele utilizou os 30%.
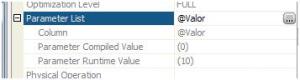
Propriedades – 3º Consulta
O valor utilizado no momento de compilação foi “0” porem no mento de RunTime
o valor mudou para “10”.
Conclusão
Bom galera, fica a dica de quando, como e porque estes problemas são
causados. Depois de entendido o problema resolve-los fica bem mais facil.
Abraço.
Deixe um comentário

Fabiano Amorim
SQL Server MVP

Meu livro, Complete ShowPlan Operators

Livro, SQL Server além do conceito

Livro, Diálogos ao vento

Livro, Diálogos com D

Salve Fabiano!, fiquei com uma duvida cara…. Dando uma estudada peguei varios conceitos (No forum inclusive) falando que o Sniffing é o problema de quanto a query EXEC dbo.proc @p1 = ‘a’ demora 2 segundos via SSMS e 10 minutos via Aplicação…mas…não consegui entender o porque…
Obrigado pelo artigo. Muito prático e de fácil entendimento.