Arquivo
Live ask-me-anything 15/10
Galera, tudo certo? Na próxima sexta-feira (15/Outubro) as 12h vou fazer uma live no estilo “me pergunte qualquer coisa”(de preferência que seja sobre SQL Server ;P). Escreva sua pergunta aqui, me envia no e-mail/linkedin/zap/facebook/instagram/twitter, ou pergunte na live que vou tentar responder.
https://www.linkedin.com/events/meperguntequalquercoisa6853643067719745536/
Abs
PDF, rascunho diálogos com D
Aproveitando o blog pra deixar documentado e publicar um texto que escrevi há algum tempo… da série vai que interessa.
Vagas no LinkedIn são fake? Ou o RH das empresas é que precisa melhorar?
Uma vez, um amigo (Marcelo Fernandes) comentou comigo que “vira e mexe” ele aplica pra vagas de emprego disponíveis por ai, mesmo sem estar interessado em mudar de emprego, a ideia é entender se ele continua sendo requisitado pelo mercado, e validar seu conhecimento técnico e não técnico utilizando o processo seletivo das empresas, e também possivelmente, até achar algo que ele não estava procurando mas que é melhor que seu emprego atual. Eu sempre achei a ideia ótima, mas nunca tinha de fato feito isso.
Esses dias enquanto eu estava navegando pelo LinkedIn, pensei, aaa, acho que vou aplicar pra algumas vagas de emprego pra ver o que vira. Vai que aparece um doido querendo me contratar né? Se a proposta for boa? Mal não vai fazer :-). Bom, eu aprendi algumas lições com isso.
Lições aprendidas.
1 – Tem muita vaga disponível pra área de banco de dados, mas a cada 1 vaga pra DBA SQL Server, tem 5 pra engenheiro de dados. Ou seja, como já era óbvio, ser um excelente administrador de banco de dados ainda é requisitado, sim, porém, ser “apenas” um DBA já não é tão valioso, é necessário entrar no mundo dos dados e aprender “novos” (de novo mesmo são apenas as ferramentas, pois os conceitos estão ai faz muito tempo, big data = data wharehouse, IA = data mining) conceitos como nuvem, big data, IA e afins.
2 – Vagas pra especialistas ainda estão disponíveis, com menor frequência, é verdade, mas ainda tem gente precisando de um especialista SQL Server. Porém, conhecer outros bancos de dados, sem dúvida é um excelente ponto a favor dos candidatos.
3 – Vagas pra Seniors dificilmente são preenchidas, eu conheço pelo menos 4 empresas procurando especialistas em SQL Server, sendo 2 gigantes (Bancos Itaú e BTG), e 2 empresas de consultoria (DataSide e PowerTuning) que crescem absurdamente a cada ano. Se você conhece MUITO de SQL Server e está procurando algo, entre em contato comigo, talvez eu possa ajudar.
Agora vamos ao ponto onde eu queria mesmo falar nesse post.
Eu apliquei pra 9 vagas de empresa no Brasil, e confesso que estou confuso com o que aconteceu, pois mesmo depois de mais de 1 mês que apliquei, eu simplesmente não recebi retorno de NENHUMA das empresas.
Isso me fez parar pra pensar, o que aconteceu? Será que meu curriculum tá muito ruim? Eu preciso de alguma indicação? Preciso melhorar em algo? Pois é, eu não sei. Eu sinceramente sempre acreditei e confiei muito no meu conhecimento, sempre foquei minha carreira em ser o melhor profissional em SQL Server do mundo, óbvio que não sou, mas tenho confiança suficiente no meu conhecimento pra dizer que conheço muito de SQL Server. Será que isso não é mais o suficiente? Dado a quantidade de pessoas que me procuram querendo ajuda com consultoria e pra resolver um problema, isso não me parece correto. Se tem tanta gente com problema me procurando e pagando uma fortuna no valor hora que eu cobro pra resolver os problemas deles, por que nenhuma empresa me respondeu? Seria eu “over qualified” pra vaga?
Bom, eu sinceramente acredito que o problema está no processo seletivo das empresas, no setor de RH mesmo.
Ora, mesmo eu sendo “over qualified” pra vaga, eu deveria ter um retorno da empresa. Se meu curriculum não for o suficiente, eu deveria ter um retorno da empresa. Não importa o que aconteça, eu sinceramente acredito que as empresas que publicam as vagas de emprego, tem a obrigação moral de contactar os candidatos e dar uma satisfação a eles. Qual o sentido em publicar uma vaga de emprego e depois de 1 mês não dar NENHUM retorno pros candidatos? Eu fico só imaginando, e se eu realmente estivesse procurando e precisando de um emprego ? Como eu ficaria nessa hora?
Me parece que o famoso QI (quem indica) ainda é necessário, só assim que funciona.
Na minha humilde opinião, o RH dessas empresas prestam um péssimo serviço e sem dúvida deixam MUITO a desejar, e é uma pena que isso aconteça.
Eu no mínimo, deveria ter recebido um “estamos analisando”, mas, nem isso recebi.
Aaaa, e pra deixar o post mais interessante, faço questão de marcar as empresas que eu apliquei pra vaga, e deixo meu blog a disposição pra caso alguém queira comentar sobre o que escrevi.
https://www.linkedin.com/jobs/view/2221528072/?refId=1000cfbd-27e2-43e5-b29d-f41f85e8423e

https://www.linkedin.com/jobs/view/2436452997/?refId=86ee9bf0-5977-46db-b407-bba04d1fcc6e

https://www.linkedin.com/jobs/view/2432821688/?refId=f39415a3-2a19-49fd-9f50-754316a051eb

https://www.linkedin.com/jobs/view/2436693929/?refId=f1e5c9c8-a4bd-4692-bf36-53b73cffce94

https://www.linkedin.com/jobs/view/2441351504/?refId=05803a86-a967-4a81-a2b5-17c1bc6a9466
https://www.linkedin.com/jobs/view/2454837815/?refId=b4c8d56a-5946-4288-9dae-a02e66726efe
https://www.linkedin.com/jobs/view/2437991259/?refId=5581a997-5651-4a7a-8408-ee2f965467c5

https://www.linkedin.com/jobs/view/2450914489/?refId=f40c2b0d-3c2e-4666-be18-855ba0838a63
https://www.linkedin.com/jobs/view/2454879087/?refId=44d02fa1-a687-4229-b3d2-d6cb8ae865e4
Abs.
Fabiano Amorim
Arquivos palestra Festival de Tecnologia MS
Fala galera, beleza?
Segue o link pra download da palestra que fiz no https://www.festivaldatecnologiams.com.br/, falei sobre otimização para queries remotas, espero que seja util ai!

https://1drv.ms/u/s!AqbKdH5H9-9StXsUu62H036Fk9Hw?e=Gg2iSl
Abs.
Fabiano
Troubleshooting de problema relacionado a I/O? é fácil…
No startup do serviço, quando o SQL faz o CreateFile pra criar o handle (armazena essa info na classe FCB) dos arquivos do banco ele usa FILE_FLAG_NO_BUFFERING pra fazer bypass do cache do Windows, e por isso ele consegue fazer I/Os de escrita menores que o cluster size (que a MS recomenda ser definido como 64KB exceto filestream). Falando nisso qual o allocation unit size você usa no seu ambiente? Concorda que 4KB é bom? Ou 64KB é melhor? Talvez 2MB?
Não entendeu muito bem o que eu escrevi ai? Quer entender? Da uma olhada no treinamento de I/O no SQL Server que gravei. https://cursos.powertuning.com.br/course?courseid=internals4
Saber responder o por que das coisas, é um diferencial que poucos tem e são de valor imensurável. Quando o ambiente parou, e o arquiteto de desenvolvimento diz que foi um problema no banco de dados, como você faz pra provar e explicar tecnicamente pra ele e pro resto do time, qual foi o motivo do problema?
Lista de 275 dicas de performance… até agora…
A lista vai longe… Pelo que percebi, vai ser sem fim… Já temos 175 dicas gravadas e disponíveis em https://cursos.powertuning.com.br/
— Parte 1
1 – Cuidado com “missing index”
2 – Cuidados com NULL
3 – Estatísticas – atualizando com valores falsos
4 – Estatísticas – colunas ascendentes
5 – Estatísticas – date correlation optimization
6 – Estatísticas – desatualizadas
7 – Estatísticas – faltando
8 – Estatísticas – gap
9 – Estatísticas – impacto em operaçoes de rebuild
10 – Estatísticas – múltiplas colunas
11 – Estressando uma consulta
12 – Indexando colunas calculadas
13 – Intersecçao de índices
14 – Like ‘%%’ – Fultext search
15 – Like Fultext search – Coringa no final + reverse
16 – Like ‘%%’ – SQL Collate
17 – Like ‘%%’ – Fragmentos de string
18 – Ordenaçao – disco HDD, performance do tempdb
19 – Ordenaçao – disco HDD, múltiplos arquivos do tempdb
20 – Ordenaçao – disco SSD, performance do tempdb
21 – Ordenaçao – disco SSD, múltiplos arquivos do tempdb
22 – Order by é necessário
23 – Pensando em sets, um exemplo
24 – Removendo LOB da página de dados
25 – Removendo lookups – Include
— Parte 2
26 – Otimizando inserçoes – Parallel insert, SQL2014+
27 – Otimizando inserçoes – Operaçoes minimamente logadas
28 – Otimizando inserçoes – SSIS + Balaced Data Distributor
29 – Otimizando inserçoes – Batch único ou vários inserts
30 – Reescrita de T-SQL – Missing spool
31 – Reescrita de T-SQL – Subquery ou CrossApply
32 – Reescrita de T-SQL – LINQ vs TOP
33 – Reescrita de T-SQL – Group by()
34 – Row goal – Forceseek
35 – Row goal – TOP N, TOP 100
36 – Evitando HP – functions schemabinding
37 – Evitando HP – evitando spool
38 – Wide e narrow plans
39 – SET ou SELECT
40 – Variáveis locais ou parâmetros de entrada
41 – Variáveis do mesmo tipo da coluna
42 – Será que seek é sempre melhor que scan
43 – Expurgo de forma eficiente
44 – Utilizando clausula output
45 – Residual predicates
46 – Prefira um “between” a “IN”
47 – Forçando paralelismo
48 – Seek – quem filtra, index seek ou predicate
49 – Otimizando algoritmo de merge join
50 – Debug tupiniquim com RAISERROR WITH NOWAIT
— Parte 3
51 – Distinct ou group by
52 – TOP 1 ORDER BY DESC ou MAX
53 – Not In ou Not Exists
54 – Subqueries ou CrossOuter apply
55 – Union all VS Union
56 – Count(1) ou Count (asterisco)
57 – Ordem da escrita do join, importa
58 – Escrevendo códigos dinâmicos com eficiência
59 – Reescrevendo OUTER JOINS complexos
60 – CTE para evitar múltiplo acesso a functions
61 – Importância do cache plan
62 – Filtros dinâmicos, utilizando “parameter embedding optimization”
63 – “Parameter embedding optimization” – limitaçao com variável
64 – Evitando recompilaçoes
65 – Minimizando tempo de compilaçao – Merge interval bug
66 – Desnormalizando para obter performance
67 – Utilizando tabela numérica auxiliar
68 – Retornando maior valor de várias colunas
69 – Tabela de sequencia + identity vs sequence
70 – WITH ENCRYPTION nao funciona… nem perca tempo
71 – Processamento em paralelo no SQL (multi threads com CLR)
72 – Scan – Removendo fragmentaçao
73 – Scan – Ajustando fillfactor
74 – Scan – Aplicando compressao de dados
75 – Scan – Scan direction e paralelismo
— Parte 4
76 – Views indexadas
77 – Indice cluster – único
78 – Indice cluster – estático
79 – Indice cluster – sequencial
80 – Indice cluster – pequeno
81 – Particionamento – eliminaçao de partiçao
82 – Indices únicos com vários valores NULL
83 – Cuidados com nolock – leituras sujas
84 – Cuidados com nolock – lendo mesma linha mais de uma vez
85 – Cuidados com nolock – pulando linhas
86 – Cuidados com nolock – mascarando erros de corrupçao
87 – Cuidado, case + subqueries
88 – Otimizando COUNT (DISTINCT…)
89 – Otimizando cursores
90 – Utilizando SET STATISTICS IO, cuidado com funçoes
91 – TOP com empate
92 – Otimizando queries utilizando linked server
93 – Cuidados com nolock – movimentaçao dos dados
94 – Validando se a tabela está vazia… o que usar
95 – Stream aggregate e compute scalar – Otimizando agregaçao
96 – Conversoes implícitas
97 – Filtros – Iniciando com ‘Z’
98 – Filtros – Removendo hora da data
99 – Minimizando compilaçao de queries ad-hoc com plan guides
100 – Convertendo scalar function em inline function
— Parte 5
101 – Criando índices hipotéticos
102 – Indices filtrados
103 – Bushy plans
104 – Hash e order group hints
105 – Planos de execuçao com “time out” na criaçao, TF8780
106 – Planos bons o suficiente
107 – Agregaçoes de vetor e agregaçoes escalares
108 – Parameter sniffing problem
109 – Aplicaçao, parametrizando corretamente – evitando cachebloat
110 – Split de string
111 – Gerando uma string delimitada
112 – Contando a quantidade de caracteres em uma string
113 – Identificando linhas duplicadas
114 – Identificando ilhas
115 – Identificando gaps
116 – Lendo valor da linha anterior
117 – Lendo valor da linha posterior
118 – Identificando valores faltando
119 – Retornando “running aggregations”
120 – Transformando linhas em colunas dinamicamente
121 – Ignorando linhas duplicadas
122 – Qual impacto de sp
123 – Qual impacto de set no count
124 – Escondendo códigos do DBA
125 – Ignorando todos os inserts
— Parte 6
126 – Retornando a quantidade de linhas de uma tabela
127 – Simulando ambiente de produçao em desenvolvimento
128 – Cuidados com performance das funçoes de janela
129 – Check constraints e sua relaçao com performance
130 – Foreign keys e sua relaçao com performance
131 – Evitando contençao de alocaçao de objetos no tempdb
132 – Utilizando variáveis do tipo tabela com eficiência
133 – Escrevendo consultas recursivas
134 – XML – Indices seletivos
135 – Paginaçao, como fazer
136 – Indices únicos e seus benefícios
137 – Force order
138 – Ajustando query wait
139 – Java + parametros unicode
140 – Obtendo mais performance com prefetch
141 – Problemas de bloqueios causados por prefetch
142 – Cuidados com SQL Injection
143 – Cuidados com ISNUMERIC
144 – IF condiçao AND condiçao ou IF condiçao IF condiçao
145 – Erro com ISNULL(ColunaQueNaoAceitaNULL) + colunas calculadas
146 – Problemas com “auto create_update statistics”
147 – Query com OPTION(MAXDOP 1) gerando wait em CXPACKET
148 – Minimizando bloqueios com indexaçao
149 – Lock escalation
150 – Melhorando performance de MIN e MAX em tabelas particionadas
— Parte 7
151 – Reescrita de T-SQL – Quebrando query utilizando tabelas temporárias
152 – Reescrita de T-SQL – Trocando JOIN + OR por CROSS APPLY e UNION
153 – Reescrita de T-SQL – Otimizando DISTINCT COUNT
154 – Reescrita de T-SQL – SARG vs NONSARG e filtros dinâmicos
155 – Reescrita de T-SQL – Otimizando query com ORDER BY e NULLS LAST
156 – Reescrita de T-SQL – Evitando sort em query com OVER(Col ORDER BY DESC)
157 – Reescrita de T-SQL – Cursor melhor que set-based
158 – Eita, eu nao sabia que da pra fazer isso (TRANSLATE)
159 – Eita, eu nao sabia que da pra fazer isso (TRIM)
160 – Eita, eu nao sabia que da pra fazer isso (CONCAT_WS)
161 – Eita, eu nao sabia que da pra fazer isso (DECLARE @c CURSOR)
162 – Eita, eu nao sabia que da pra fazer isso (AS Tab(ColName))
163 – Eita, eu nao sabia que da pra fazer isso (DROP TABLE Tab1, Tab2)
164 – Eita, eu nao sabia que da pra fazer isso (TRUNCATE com WHERE)
165 – Utilizando otimizaçao de insert mais rápido no SQL2014+ e tempdb
166 – Testando hyper-threading
167 – CachePlan – Simple – AutoParam
168 – CachePlan – Cuidados com parameterizaçao na App e TF144
169 – CachePlan – Optimize for adhoc workloads.json
169 – CachePlan – Optimize for adhoc workloads
170 – CachePlan – sp_prepare vs direct exec
171 – CachePlan – Textos iguais, hash tem que bater
172 – CachePlan – Plan Reuse-affecting set options
173 – Apagando um índice para deixar uma consulta mais rápida
174 – Comprimindo VARCHAR(MAX) com ColumnStore
175 – Deu ruim quando liguei read commited snapshot isolation level
— Ainda não publicado:
— Parte 8 (edição TraceFlags)
176 – Utilizando traceflag 174
177 – Utilizando traceflag 610
178 – Utilizando traceflag 715
179 – Utilizando traceflag 1117
180 – Utilizando traceflag 2335
181 – Utilizando traceflag 2371
182 – Utilizando traceflag 2453
183 – Utilizando traceflag 2505
184 – Utilizando traceflag 2548
185 – Utilizando traceflag 3042
186 – Utilizando traceflag 3226
187 – Utilizando traceflag 7412
188 – Utilizando traceflag 7470
189 – Utilizando traceflag 7471
190 – Utilizando traceflag 8602
191 – Utilizando traceflag 8666
192 – Utilizando traceflag 8677
193 – Utilizando traceflag 8690
194 – Utilizando traceflag 8722
195 – Utilizando traceflag 8755
196 – Utilizando traceflag 8757
197 – Utilizando traceflag 9130
198 – Utilizando traceflag 9389
199 – Utilizando traceflag 9481
200 – Utilizando traceflag 9495
— Parte 9 (edição SQL2019)
201 – Batch mode over row store
202 – Batch mode over row store, Internals
203 – Row mode memory grant feedback
204 – Table variable deferred compilation – Demo 1
205 – Table variable deferred compilation – Demo 2
206 – Scalar UDF inlining – 1
207 – Scalar UDF inlining – 2 (bad case)
208 – Accelerated database recovery – Demo 1
209 – Accelerated database recovery – Demo 2
210 – Lightweight query plan ligado por padrao
211 – sys.dm_exec_query_plan_stats
212 – Compression estimates para column store
213 – Novo wait (WAIT_ON_SYNC_STATISTICS_REFRESH)
214 – Suporte a persisted memory
215 – Emulando PMEM (persisted memory) no Linux
216 – APPROX_COUNT_DISTINCT
217 – Novos hints – sys.dm_exec_valid_use_hints
218 – sys.dm_db_page_info
219 – Tempdb in-memory system objects
220 – Transparent Data Encryption (TDE) scan – suspend and resume
221 – Reduçao de recompilaçao para workloads utilizando tabelas temporárias
222 – Suporte a UTF-8
223 – Resume e Pause para criaçao de índices online
224 – Criaçao de índices columnstore online
225 – Improved indirect checkpoint scalability
— Parte 10
226 – Permissao LinkedServer SQL2008R2
227 – Filtros LinkedServer Local VS Remote
228 – LinkedServer vs sp_prepexec e sp_execute
229 – LinkedServer INNER REMOTE JOIN
230 – LinkedServer collation compatible
231 – LinkedServer vs halloween protection
232 – LinkedServer vs MARS
233 – View indexada vs Blocks e DeadLocks
234 – Nível de isolamento vs Entity Framework
235 – Nível de isolamento padrao, lock em select
236 – Lock extra de query rodando em paralelo
237 – Lock extra de query acessando LOB
238 – Lock extra de query com halloween protection
239 – Impacto de conexoes com MARS habilitado
240 – Problema de performance com funçao FORMAT
241 – Memory leak no JDBC
242 – Ajustando cost threshold for parallelism
243 – Troubleshoot com windows performance toolkit
244 – Otimizando velocidade dos backups
245 – A significant part of sql server process memory has been paged out…
246 – BP data cache – free_space_in_bytes e fragmentaçao
247 – BP data cache – utilizando compressao de dados
248 – BP data cache – entendendo page disfavoring
249 – Obtendo informaçoes uteis do default trace
250 – Analisando deadlock envolvendo apenas uma tabela
— Parte 11
251 – Operador do plano de execução – IndexSeek
252 – Operador do plano de execução – Table Spool (Lazzy Spool)
253 – Operador do plano de execução – Table Spool (Eager Spool)
254 – Operador do plano de execução – Index Spool
255 – Operador do plano de execução – KeyLookup apenas pra fazer predicate
256 – Operador do plano de execução – RowCount Spool
257 – Operador do plano de execução – Merge interval
258 – Operador do plano de execução – Split, Sort e Collapse
259 – Operador do plano de execução – Loop join
260 – Operador do plano de execução – Merge join
261 – Operador do plano de execução – Hash join
262 – Operador do plano de execução – Hash join vs residual predicate
263 – Operador do plano de execução – Adaptive join
264 – Foldable expressions
265 – NonUpdating updates
266 – Group hints
267 – DBCC OPTIMIZER_WHATIF
268 – Ligando e desligando optimizer query rules
269 – xEvent – inaccurate_cardinality_estimate
270 – QO Bug, Expressions In Queries
271 – QO Bug, IS NOT NULL
272 – QO Bug, Produto Cartesiano
273 – QO Bug, Segment Operator
274 – QO Bug, Filter VS Aggregation
275 – QO Bug, MERGE
Video, disk I/O no SQL Server
Quando eu gravei esse vídeo, minha cabeça tava tão maluca e com tanta informação… Eu havia pesquisado e estudado tanto nos últimos meses que hoje consigo ver no vídeo o quão maluco eu estava rs… Esse treinamento é meu orgulho, se você ainda não viu esse vídeo e usa SQL Server, assista…
Abs.
Fabiano
Scripts, Live DBA Solidário, DBA Brasil
De volta com um treinamento presencial em SP
Fala galera, confesso que eu estava ansioso pra escrever esse post.
Indo direto ao ponto, esse ano voltarei a ministrar um treinamento presencial, e vai ser o mais maluco/completo que já ministrei.
A ementa provavelmente será a seguinte:
1 – Internals – SQLOS, Waits e CPU
2 – Internals – Memória Parte 1
3 – Internals – Memória Parte 2
4 – Internals – Disk I/O
5 – Internals – Latch, Spinlock e TempDB
6 – Internals – Índices, Otimizador de consultas e estatísticas
7 – Internals – Gerenciamento de concorrência e performance tuning parte 1
8 – Internals – Segurança e performance tuning parte 2 + graduação dos sobreviventes e/ou enlouquecidos.
Local: Treinamento presencial em São Paulo-SP.
Carga horária: 64 horas. (praticamente uma faculdade)Quando: Datas e horários a definir.
Horário provavelmente será no integral aos sábados ou no período noturno, ainda vou decidir.
Datas provavelmente em Julho e Agosto.
Valor: R$ 5.000,00 (cinco mil reais) (vou pensar numa forma de parcelar esse valor pra facilitar)
Obviamente estou contanto que teremos voltado ao “quase normal’ com a vacinação e que a pandemia esteja mais controlada.
As vagas serão limitadas portanto se você quer reservar sua vaga, por favor me envie um e-mail ou me chama no Zap o quanto antes pra gente conversar.
Abs.
Fabiano
Reorganize e o impacto gerado por bloqueios
Vamos lá, comecei a escrever um texto pra falar sobre bloqueios e vi que ele estava ficando muito grande, então eu assumi que ele ia ficar grande e aproveitei pra fazer um texto mais completo.
Pra entender um pouco mais sobre como funcionam os bloqueios e qual o impacto de um Reorganize, vamos começar com um simples exemplo e detalhar o que o SQL está fazendo.
Preparando o ambiente
Criando uma tabela pra usar nos testes.
USE Northwind
GO
— Preparar ambiente…
— 2 segundos para rodar
IF OBJECT_ID(‘OrdersBig’) IS NOT NULL
DROP TABLE OrdersBig
GO
SELECT TOP 1000000
IDENTITY(Int, 1,1) AS OrderID,
ABS(CheckSUM(NEWID()) / 10000000) AS CustomerID,
CONVERT(Date, GETDATE() – (CheckSUM(NEWID()) / 10000000)) AS OrderDate,
ISNULL(ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))),0) AS Value,
CONVERT(VARCHAR(250), NEWID()) + CONVERT(VARCHAR(250), NEWID()) + CONVERT(VARCHAR(250), NEWID()) AS ColNewID
INTO OrdersBig
FROM master.dbo.sysobjects A
CROSS JOIN master.dbo.sysobjects B CROSS JOIN master.dbo.sysobjects C CROSS JOIN master.dbo.sysobjects D
GO
ALTER TABLE OrdersBig ADD CONSTRAINT xpk_OrdersBig PRIMARY KEY(OrderID)
GO
Testes de um select simples utilizando com nível de isolamento padrão (READ COMMITTED)
Agora, suponhamos que eu rode o seguinte comando:
SELECT OrderID FROM Northwind.dbo.OrdersBig WHERE OrderID <= 3

Vou usar o sqlcmd pra rodar o select, o comando fica assim:
sqlcmd -S razerfabiano\sql2019 -U Login1 -P @bc12345 -Q “SELECT OrderID FROM Northwind.dbo.OrdersBig WHERE OrderID <= 3”

Internamente os bloqueios gerados ficam assim:
- Inicia uma transação implícita pro o comando, ou seja, todos os bloqueios serão controlados no escopo dessa transação. Pra esse caso, vamos considerar que TransactionID é 18935
- Adquire um S lock no banco Northwind
- Adquire um IS lock no objeto OrdersBig
- Adquire um IS lock no arquivo/página (1:85896)
- Adquire um S lock na linha (KEY) com o OrderID = 1, %%lockres%% = (8194443284a0)
- Libera o S lock na linha (KEY) com o OrderID = 1
- Adquire um S lock na linha (KEY) com o OrderID = 2, %%lockres%% = (61a06abd401c)
- Libera o S lock na linha (KEY) com o OrderID = 2
- Adquire um S lock na linha (KEY) com o OrderID = 3, %%lockres%% = (98ec012aa510)
- Libera o S lock na linha (KEY) com o OrderID = 3
- Libera o IS lock no arquivo/página (1:85896)
- Libera o IS lock no objeto OrdersBig
- Libera o S lock no banco Northwind
É possível ver essa sequência de eventos acontecendo utilizando o profiler para capturar os eventos de lock.
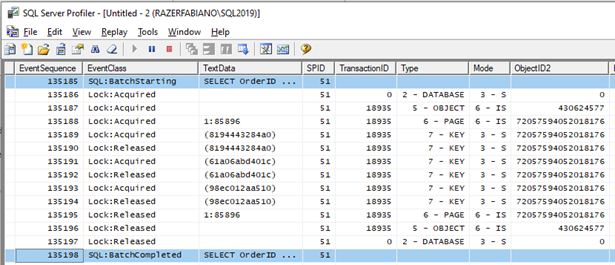
Algumas informações importantes em relação aos eventos:
- Um S lock é utilizado na linha pra garantir que enquanto a linha está sendo lida ninguém pode modifica-la. Ou seja, se enquanto o SQL estiver lendo a linha alguma sessão tentar fazer uma modificação nessa linha, ela ficará bloqueada.
- Repare que utilizando o nível de isolamento padrão (READ COMMITED), assim que uma linha é lida, o bloqueio é liberado, ou seja, o tempo que um LOCK de leitura é mantido na linha tende a ser muito rápido.
-
Intent lock é um conceito importante e que você precisa conhecer. Se quiserem falar mais sobre isso me avisa que eu preparo algo.
Testes do select com READUNCOMMITTED/NOLOCK
Se eu rodar a mesma query, porém utilizando o hint READUNCOMMITTED ou NOLOCK eu evito que uma sessão tentando alterar a linha fique bloqueada, porém corro o risco de ler dados sujos e etc (todos os outros problemas que já falei sobre NOLOCK, ver treinamento de dicas).
Só pra deixar a sequencia de eventos, a query com NOLOCK fica assim:


Como podemos ver no print do profiler, temos apenas um S lock no banco e um Sch-S lock na tabela pra evitar que a estrutura dela seja modificada enquanto a leitura está ocorrendo. Ou seja, uma query com NOLOCK pode gerar bloqueios de comandos DDL.
Testes do select com REPEATABLE/SERIALIZABLE READ
Com REPEATABLE/SERIALIZABLE READ o SQL precisa garantir que a leitura de uma linha terá o mesmo valor até o termino da query, ou seja, o lock na linha só será liberado quando todas as linhas forem lidas, diferente do comportamento em READ COMMITTED que libera o lock assim que a linhas é lida.


Consideração importante em relação aos níveis de isolamento mais pessimistas como REPEATABLE READ e SERIALIZABLE:
- Infelizmente, é muito comum os desenvolvedores utilizarem o nível de isolamento equivocado, ou seja, uma conexão que deveria utilizar um READ COMMITTED é aberta com SERIALIZABLE e isso passa a gerar uma série de locks (que podem gerar um lock escalation pra tabela) totalmente desnecessários e mais demorados, gerando bloqueios.
Exemplo de problema com Entity Framework
Criei uma aplicaçãozinha tosca que usa EF pra ler a tabela OrdersBig, a tela ficou assim:

O botão “button2” faz o seguinte:
private void button2_Click(object sender, EventArgs e)
{
using (System.Transactions.TransactionScope scope = new System.Transactions.TransactionScope(TransactionScopeOption.RequiresNew))
{
var v1 = new NorthwindEntities();
// Te dou um prêmio se você adivinhar qual é o IsolationLevel default…
// MessageBox.Show(Transaction.Current.IsolationLevel.ToString());
dataGridView1.DataSource = v1.OrdersBigs.Take(20000).ToList();
scope.Complete();
v1.Database.Connection.Close();
}
}
Estou usando tudo default e nada complexo, só iniciando uma transação e lendo as primeiras 20 mil linhas da tabela OrdersBig. Adivinha qual o nível de isolamento será utilizado?
Vamos ver o que o SQL nos diz em relação a essa sessão aberta pelo EF.
SELECT session_id, login_time, host_name, program_name, open_transaction_count,
CASE transaction_isolation_level
WHEN 0 THEN ‘Unspecified’
WHEN 1 THEN ‘Read Uncommitted’
WHEN 2 THEN ‘Read Committed’
WHEN 3 THEN ‘Repeatable Read’
WHEN 4 THEN ‘Serializable’
WHEN 5 THEN ‘Snapshot’
END AS [Transaction Isolation Level]
FROM sys.dm_exec_sessions
WHERE program_name LIKE ‘Entity%’
GO

Pois é, como eu disse, é preciso cuidado por parte dos desenvolvedores e atenção no monitoramento dos DBAs.
Olha o que esse select gerou de locks.
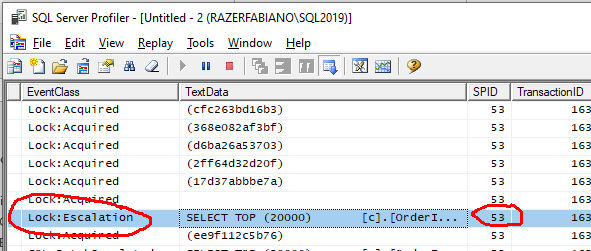
Além dos locks nas linhas até a query terminar, um lock escalation, tenso.
Testes com comando gerando modificações na tabela
Vamos supor o seguinte update pra atualizar 3 linhas da tabela OrdersBig:
UPDATE OrdersBig SET ColNewID =
‘Fabiano’
WHERE OrderID <= 3
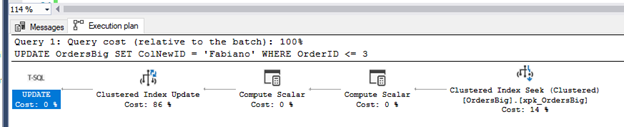
Vou usar o sqlcmd pra rodar o select, o comando fica assim:
sqlcmd -S razerfabiano\sql2019 -U Login1 -P @bc12345 -Q “UPDATE Northwind.dbo.OrdersBig SET ColNewID = ‘Fabiano’ WHERE OrderID <= 3”

Internamente os bloqueios gerados ficam assim:
- Inicia uma transação implícita pro o comando, ou seja, todos os bloqueios serão controlados no escopo dessa transação. Pra esse caso, vamos considerar que TransactionID é 566400
- Adquire um S lock no banco Northwind
- Adquire um IX lock no objeto OrdersBig
- Adquire um IX lock no arquivo/página (1:85896)
- Adquire um X lock na linha (KEY) com o OrderID = 1, %%lockres%% = (8194443284a0)
- Adquire um X lock na linha (KEY) com o OrderID = 2, %%lockres%% = (61a06abd401c)
- Adquire um X lock na linha (KEY) com o OrderID = 3, %%lockres%% = (98ec012aa510)
- Libera o X lock na linha (KEY) com o OrderID = 1
- Libera o X lock na linha (KEY) com o OrderID = 2
- Libera o X lock na linha (KEY) com o OrderID = 3
- Libera o IX lock no arquivo/página (1:85896)
- Libera o IX lock no objeto OrdersBig
- Libera o S lock no banco Northwind
Novamente, conseguimos ver essa sequência de eventos acontecendo no profiler.

Até aqui, não temos novidades, o SQL pega um X lock em cada linha modificada e só libera quando todas as linhas forem modificadas, e tudo isso ocorre dentro do contexto de uma transação.
Mas e como ficam os bloqueios das leituras e as modificações geradas por um Reorganize?
Locks gerados por um reorganize
Bom, diz a lenda que um reorganize é lindo, é online e pode ser parado a qualquer momento sem crise.
Utilizando palavras da MS
“Reorganizing an index uses minimal system resources and is an online operation. This means long-term blocking table locks are not held and queries or updates to the underlying table can continue during the ALTER INDEX REORGANIZE transaction.”.
O truque pra que o reorganize não gere bloqueios é que ele não roda no contexto de uma única transação. (a não ser que você use uma transação explicita, ver https://github.com/MicrosoftDocs/sql-docs/pull/4011 do Mr. Rodrigo)
Vejamos isso na prática.
Dessa vez, pra monitorar os bloqueios gerados, além do profiler, vou usar também a “sp_whoisactive @get_locks = 1”.
Considerando então um:
ALTER
INDEX
ALL
ON Northwind.dbo.OrdersBig REORGANIZE
Enquanto o reorganize estava rodando, chamei a “sp_whoisactive @get_locks = 1” e o xml da coluna locks é o seguinte:
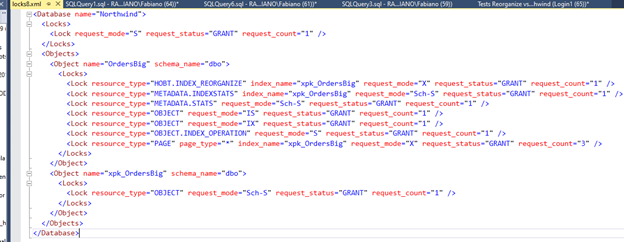
E no profiler temos o seguinte (estou exibindo apenas os dados relevantes).
SQL começa fazendo bloqueios internos, repare que o TransactionID é o 4670676.

Depois já podemos ver que ele cria várias pequenas transações, pra evitar longos bloqueios. Repare no TransactionID mudando.
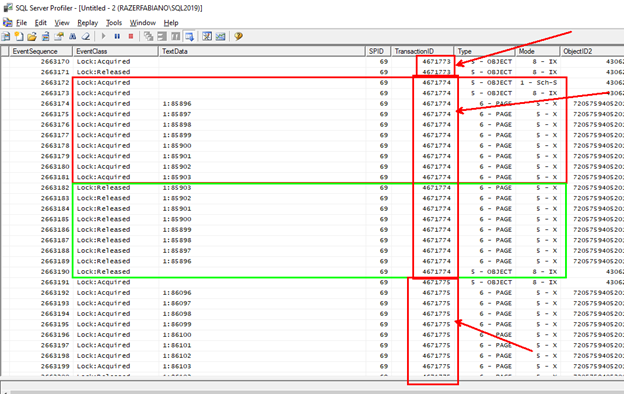
Por fim, antes de terminar ele libera os bloqueios inicias do TransactionID 4670676.

Alguns comentários em relação a isso.
Aaaa, Fabiano, mas ele pegou um IX na tabela, isso ae não pode gerar problema? Vamos considerar os cenários que vimos nesse artigo.
Vamos pegar a tabela de compatibilidade de locks do help pra nos ajudar.
|
Existing granted mode |
|||||
| Requested mode |
IS – Tabela |
S |
U |
IX – Tabela |
X – Página |
| Intent shared (IS) |
Yes |
Yes |
Yes |
Yes |
No |
| Shared (S) |
Yes |
Yes |
Yes |
No |
No |
| Update (U) |
Yes |
Yes |
No |
No |
No |
| Intent exclusive (IX) |
Yes |
No |
No |
Yes |
No |
| Exclusive (X) |
No |
No |
No |
No |
No |
Eu realcei em vermelho os locks que o reorganize vai gerar, são eles: IS + IX na tabela e um X na página. Considerando esses locks operações ficariam bloqueadas?
“Select simples” – Primeiro exemplo que vimos nesse artigo.
Conforme vimos, um select simples gerou um IS na tabela, IS na página e alguns S nas linhas lidas. Olhando na tabela, podemos ver que quando o select tentar fazer um IS na página que já tem um X (já obtido pelo reorganize), ele vai ficar bloqueado. Portanto, sim o reorganize pode gerar bloqueios, podem na minha opinião eles serão extremamente rápidos, pois, lembre-se, o reorganize vai liberar o lock X na página assim que terminar a pequena transação que ele criou.
“Select com nolock”
O select com nolock não gerou locks na tabela, página ou linha, apenas um schema lock. Portanto o reorganize não causaria bloqueio.
“Select com serializable gerando lock escalation”
A demo com o aplicativo .net consultando o banco via EF gera os seguintes locks: IS na tabela, IS na página e um S nas linhas sendo lidas, também após atingir o threshold ( +- 5 mil locks) necessário pra disparar o lock escalation, o SQL “promoveu” o IS na tabela já obtido pra S.
Nesse cenário, a sessão ficará bloqueada quando tentar fazer IS na página que já tem um X (já obtido pelo reorganize), porém conforme eu já mencionei, esse bloqueio será muito rápido. Mas, o que vai acontecer quando o lock escalation ocorrer e ele tentar fazer um S na tabela? De acordo com a tabela de compatibilidades, um S na tabela
não é compatível com o IX na tabela já obtido pelo reorganize, sendo assim, o escalation não vai acontecer e o SQL vai continuar fazendo os locks nas linhas, uma nova tentativa de promover o IS pra S (lock escalation) será efetuada a cada 1250 novos locks obtidos. No nosso caso, ele não vai conseguir fazer o escalation nunca, pois o IX na tabela só será liberado quando o reorganize terminar.
Conclusão
Eu queria fazer outros testes, e ver outros cenários, mas já estou cansado e deu por hoje.

Fabiano Amorim
SQL Server MVP

Meu livro, Complete ShowPlan Operators

Livro, SQL Server além do conceito

Livro, Diálogos ao vento

Livro, Diálogos com D
